OpenAI
本指南介绍了将OpenAI的大型语言模型(LLMs)与Pinecone(称为 OP stack )集成的方法,增强LLMs的语义搜索或“长期记忆”。此组合利用LLMs的嵌入和完成(或生成)端点,以及Pinecone的向量搜索功能,进行微妙的信息检索。
LLMs like OpenAI's text-embedding-ada-002 generate vector embeddings, numerical representations of text semantics. These embeddings facilitate semantic-based rather than literal textual matches. Additionally, LLMs like gpt-4 or gpt-3.5-turbo predict text completions based on previous context.
Pinecone是专为存储和查询高维向量而设计的向量数据库。它提供了对这些向量嵌入的快速,高效的语义搜索。
通过将OpenAI的LLMs与Pinecone集成,我们将嵌入生成的深度学习能力与高效的向量存储和检索相结合。这种方法超越了传统的基于关键字的搜索,提供了上下文感知的精确结果。
有许多集成这两个工具的方法,我们有几个指南专注于特定的用例。如果您已经知道自己想做什么,可以跳转到这些特定的材料:
嵌入式介绍
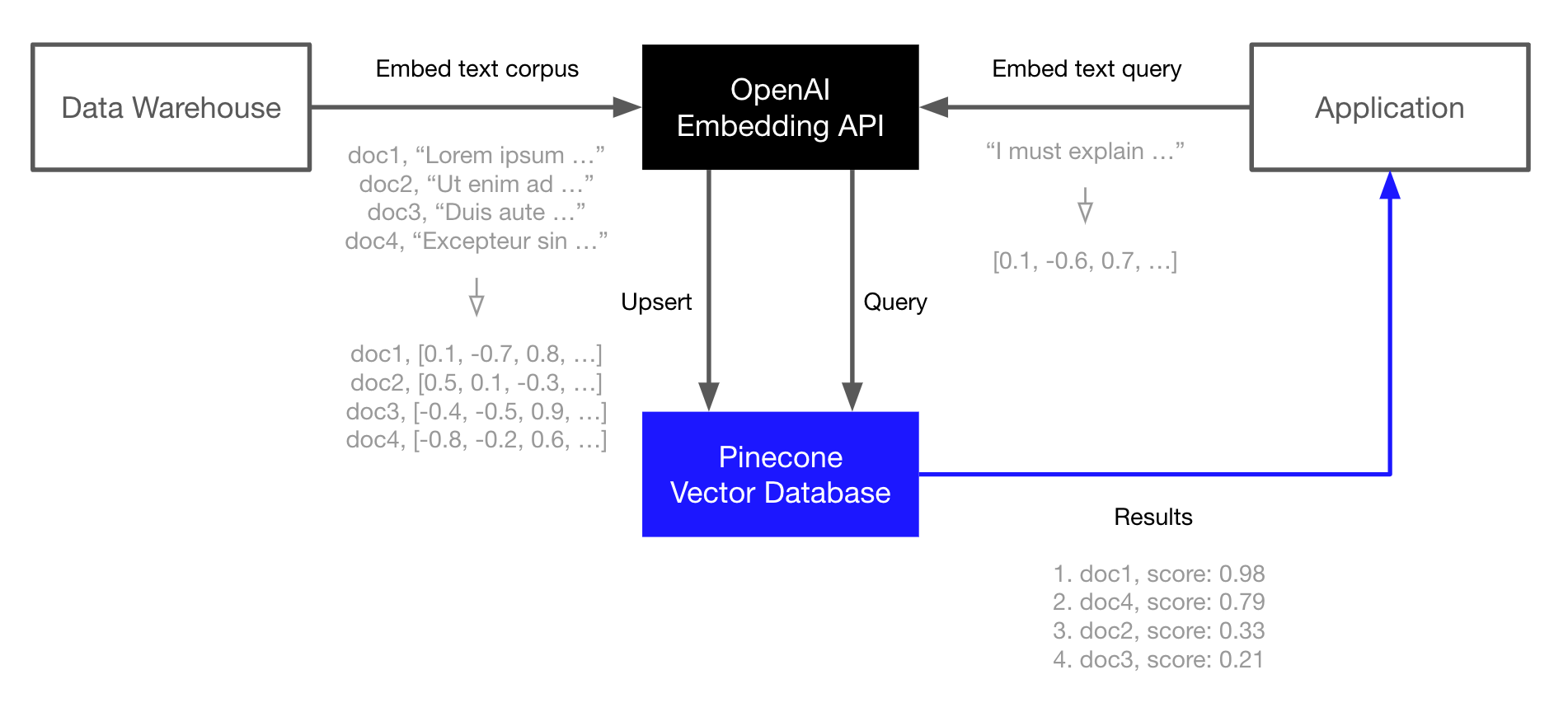
在OP堆栈的核心,我们有通过OpenAI Embedding API支持的嵌入式。我们在Pinecone向量数据库中索引这些嵌入式,以便快速和可伸缩地检索增强我们的LLMs或其他信息检索用例。
这个例子演示了核心OP堆栈。它是最简单的工作流程,在其他工作流程中也存在,但不是使用堆栈的唯一方式。请参考上面的链接了解更高级的用法。
OP堆栈是为语义搜索、问答、威胁检测和其他依赖于语言模型和大量文本数据的应用程序构建的。
基本工作流程如下:
嵌入和索引
- 使用OpenAI嵌入式API生成您的文档(或任何文本数据)的向量嵌入。
- 将这些向量嵌入上传到Pinecone中,它可以存储和索引数百万/数十亿个这些向量嵌入,并以极低的延迟搜索它们。
搜索
- 再次通过OpenAI嵌入式API传递您的查询文本或文档。
- 将结果的向量嵌入作为查询发送到Pinecone。
- 获取语义相似的文档,即使它们不与查询共享任何关键字。
让我们开始吧...
环境设置
我们先安装OpenAI和Pinecone客户端,还需要HuggingFace Datasets来下载我们在本指南中使用的TREC数据集。
Bash
pip install -U openai pinecone-client datasets
创建嵌入
要创建嵌入,我们必须首先初始化与OpenAI Embeddings的连接,我们可以在OpenAI上注册API密钥。
Python
import openai
openai.api_key = "<<YOUR_API_KEY>>"
# get API key from top-right dropdown on OpenAI website
openai.Engine.list() # check we have authenticated
The openai.Engine.list() function should return a list of models that we can use. We will use OpenAI's Ada 002 model.
Python
MODEL = "text-embedding-ada-002"
res = openai.Embedding.create(
input=[
"Sample document text goes here",
"there will be several phrases in each batch"
], engine=MODEL
)
在 res 中,我们可以发现一个类似 JSON 的对象,其中包含两个 1536 维嵌入向量,这些向量是上述两个输入的向量表示。若要直接访问这些嵌入,请执行以下操作:
Python
# extract embeddings to a list
embeds = [record['embedding'] for record in res['data']]
稍后,我们将使用此逻辑创建TREC问题分类数据集的嵌入。
初始化Pinecone索引
接下来,我们初始化一个索引来存储向量嵌入。为此,我们需要一个Pinecone API密钥,在这里注册。
Python
import pinecone
# initialize connection to pinecone (get API key at app.pinecone.io)
pinecone.init(
api_key="YOUR_API_KEY",
environment="YOUR_ENV" # find next to API key in console
)
# check if 'openai' index already exists (only create index if not)
if 'openai' not in pinecone.list_indexes():
pinecone.create_index('openai', dimension=len(embeds[0]))
# connect to index
index = pinecone.Index('openai')
填充索引
有了OpenAI和Pinecone的连接初始化,我们就可以开始填充索引了。为此,我们需要TREC数据集。
Python
from datasets import load_dataset
# load the first 1K rows of the TREC dataset
trec = load_dataset('trec', split='train[:1000]')
然后,我们使用 OpenAI 为每个问题创建一个向量嵌入(就像之前演示的那样),并将每个短语的 ID、向量嵌入和原始文本upsert到 Pinecone 中。
⚠️警告
高基数元数据值(例如我们在此处使用的唯一文本值)
可能会减少单个pod中适合的向量数量。有关更多信息,请参见限制。
Python
from tqdm.auto import tqdm # this is our progress bar
batch_size = 32 # process everything in batches of 32
for i in tqdm(range(0, len(trec['text']), batch_size)):
# set end position of batch
i_end = min(i+batch_size, len(trec['text']))
# get batch of lines and IDs
lines_batch = trec['text'][i: i+batch_size]
ids_batch = [str(n) for n in range(i, i_end)]
# create embeddings
res = openai.Embedding.create(input=lines_batch, engine=MODEL)
embeds = [record['embedding'] for record in res['data']]
# prep metadata and upsert batch
meta = [{'text': line} for line in lines_batch]
to_upsert = zip(ids_batch, embeds, meta)
# upsert to Pinecone
index.upsert(vectors=list(to_upsert))
查询
有了我们的数据已经建立索引,现在我们准备进行搜索。这个过程与建立索引类似。我们从一个文本query开始,想要使用它来查找相似的句子。与之前类似,我们使用 OpenAI 的文本相似性 Babbage 模型对它进行编码,生成一个查询向量 xq。然后,我们使用 xq 查询 Pinecone 索引。
Python
query = "What caused the 1929 Great Depression?"
xq = openai.Embedding.create(input=query, engine=MODEL)['data'][0]['embedding']
现在我们进行查询。
Python
res = index.query([xq], top_k=5, include_metadata=True)
Pinecone 的响应包含了 metadata 字段中我们的原始文本,让我们输出相似度最高的 top_k 个问题及其相似度分数。
Python
for match in res['matches']:
print(f"{match['score']:.2f}: {match['metadata']['text']}")
[Out]:
0.95: Why did the world enter a global depression in 1929 ?
0.87: When was `` the Great Depression '' ?
0.86: What crop failure caused the Irish Famine ?
0.82: What caused the Lynmouth floods ?
0.79: What caused Harry Houdini 's death ?
看起来不错,让我们加大难度,将“抑郁”替换为不正确的词汇“经济衰退”。
Python
query = "What was the cause of the major recession in the early 20th century?"
# create the query embedding
xq = openai.Embedding.create(input=query, engine=MODEL)['data'][0]['embedding']
# query, returning the top 5 most similar results
res = index.query([xq], top_k=5, include_metadata=True)
for match in res['matches']:
print(f"{match['score']:.2f}: {match['metadata']['text']}")
[Out]:
0.92: Why did the world enter a global depression in 1929 ?
0.85: What crop failure caused the Irish Famine ?
0.83: When was `` the Great Depression '' ?
0.82: What are some of the significant historical events of the 1990s ?
0.82: What is considered the costliest disaster the insurance industry has ever faced ?
最后一次搜索,我们使用“抑郁”的定义而不是这个词或相关词。
Python
query = "Why was there a long-term economic downturn in the early 20th century?"
# create the query embedding
xq = openai.Embedding.create(input=query, engine=MODEL)['data'][0]['embedding']
# query, returning the top 5 most similar results
res = index.query([xq], top_k=5, include_metadata=True)
for match in res['matches']:
print(f"{match['score']:.2f}: {match['metadata']['text']}")
[Out]:
0.93: Why did the world enter a global depression in 1929 ?
0.83: What crop failure caused the Irish Famine ?
0.82: When was `` the Great Depression '' ?
0.82: How did serfdom develop in and then leave Russia ?
0.80: Why were people recruited for the Vietnam War ?
从这个例子可以清楚地看出,语义搜索流程能够清楚地识别每个查询之间的含义。使用这些嵌入与Pinecone一起,我们可以从已索引的TREC数据集中返回最具语义相似性的问题。
更新于22天前