hugging-face-endpoints
拥抱面推理端点允许访问简单的模型推理。结合Pinecone,我们可以轻松生成和索引高质量的向量嵌入。
让我们通过初始化生成向量嵌入的推理端点来开始吧。
端点
我们首先前往拥抱面推理端点主页,如果需要,注册一个账号。注册成功后,我们应该能够看到这个页面:
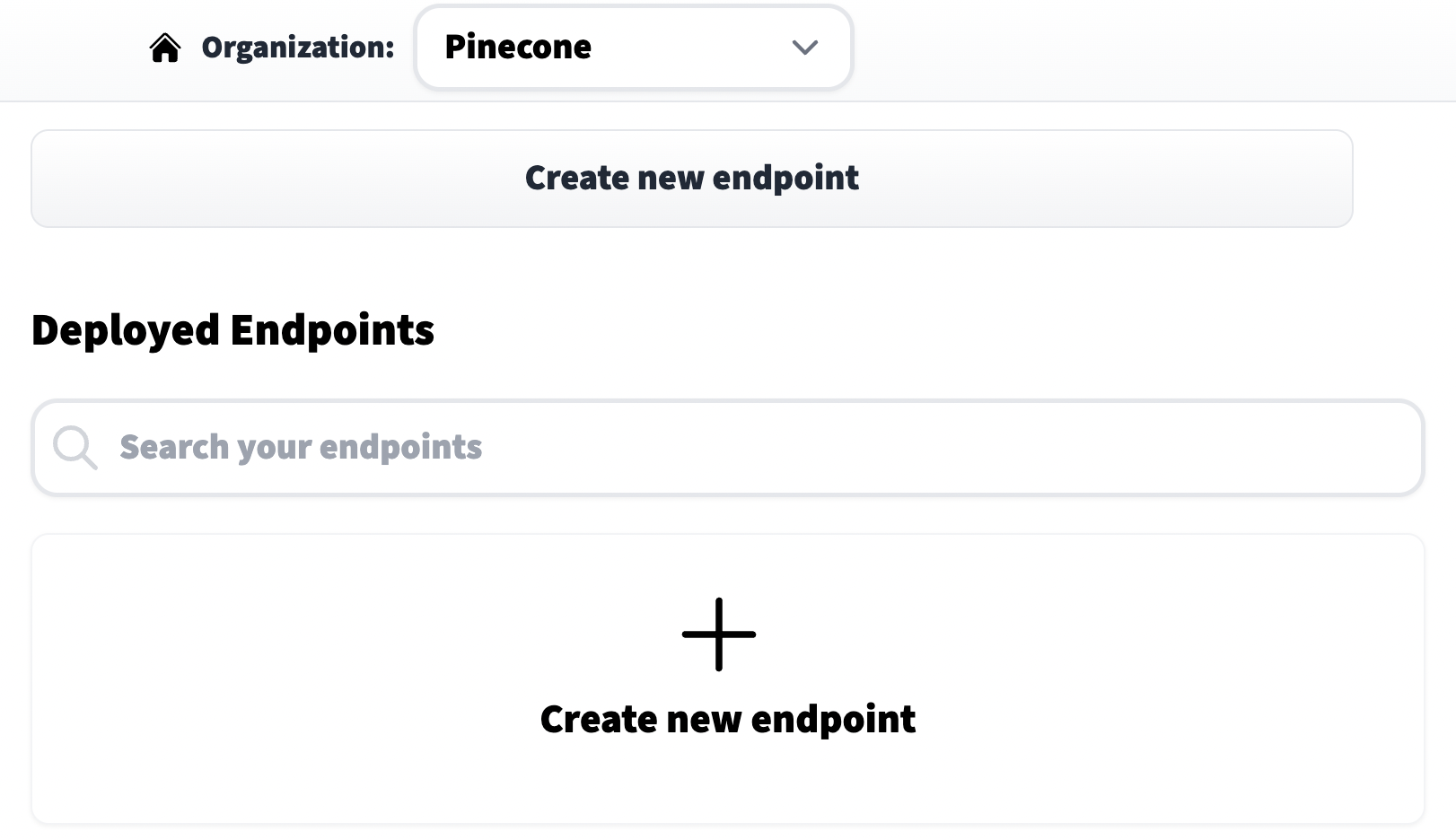
我们点击创建新端点,选择一个模型仓库(例如模型名称)、端点名称(可以随意选择)和选择一个云环境。在继续之前,非常重要的是,我们需要在高级配置设置中将任务设置为句子嵌入。
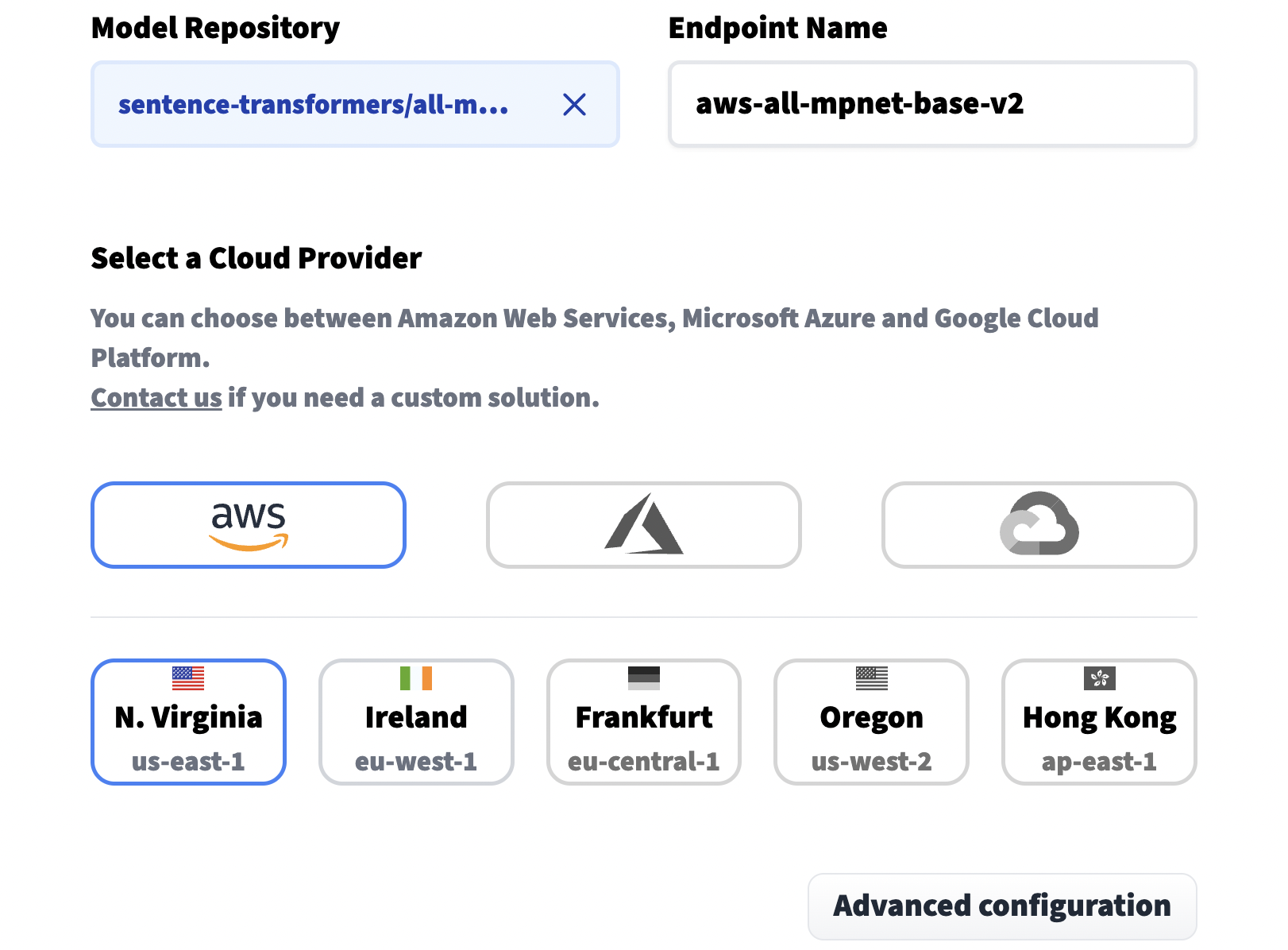

其他重要的选项包括实例类型,默认情况下使用CPU,这更便宜但速度较慢。对于更快的处理,我们需要使用GPU实例。最后,我们在页面末尾设置隐私设置。
在设置好选项后,我们可以点击页面底部的创建端点。这个操作应该会带我们到下一页,在那里我们将看到我们端点的当前状态。

一旦状态从构建中变为运行中(这可能需要一些时间),我们就可以开始使用它创建嵌入。
创建嵌入
每个端点都有一个端点URL,可以在端点概述页面上找到。我们需要将此端点URL分配给endpoint_url变量。

Python
endpoint_url = "<<ENDPOINT_URL>>"
api_org = "<<ORG_API_TOKEN>>"
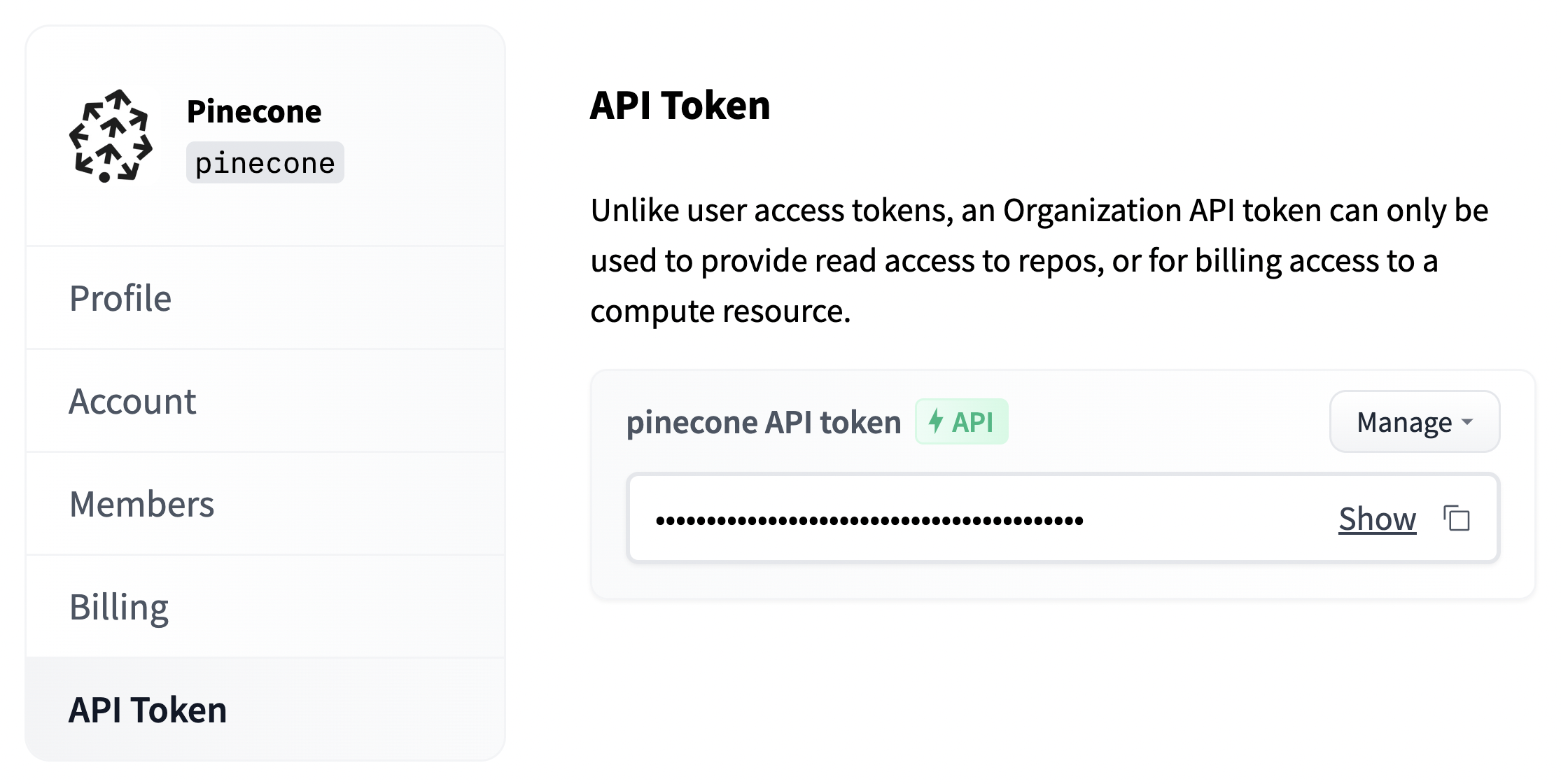
Python
api_org = "<<API_ORG_TOKEN>>"
现在我们已经准备好通过推理端点创建嵌入了。让我们从一个玩具示例开始。
Python
import requests
# add the api org token to the headers
headers = {
'Authorization': f'Bearer {api_org}'
}
# we add sentences to embed like so
json_data = {"inputs": ["a happy dog", "a sad dog"]}
# make the request
res = requests.post(
endpoint,
headers=headers,
json=json_data
)
我们应该看到一个200响应。
Python
res
<Response [200]>
在响应中,我们应该找到两个嵌入...
Python
len(res.json()['embeddings'])
2
我们还可以这样看到嵌入的维度:
Python
dim = len(res.json()['embeddings'][0])
dim
768
我们需要更多的条目来搜索,所以让我们下载一个更大的数据集。为此,我们将使用Hugging Face数据集。
Python
from datasets import load_dataset
snli = load_dataset("snli", split='train')
snli
Downloading: 100%|██████████| 1.93k/1.93k [00:00<00:00, 992kB/s]
Downloading: 100%|██████████| 1.26M/1.26M [00:00<00:00, 31.2MB/s]
Downloading: 100%|██████████| 65.9M/65.9M [00:01<00:00, 57.9MB/s]
Downloading: 100%|██████████| 1.26M/1.26M [00:00<00:00, 43.6MB/s]
Dataset({
features: ['premise', 'hypothesis', 'label'],
num_rows: 550152
})
SNLI包含550K个句子对,其中许多包括重复项,因此我们只取其中一个集合(假设)并去重。
Python
passages = list(set(snli['hypothesis']))
len(passages)
480042
我们将减少到50K个句子,这样示例就可以快速运行,如果您有时间,可以保留全部480K个句子。
Python
passages = passages[:50_000]
Vector DB
现在,我们已经准备好了端点和数据集,我们唯一缺少的就是向量数据库。为此,我们需要初始化与Pinecone的连接,这需要一个免费的API密钥。
Python
import pinecone
# initialize connection to pinecone (get API key at app.pinecone.io)
pinecone.init(api_key="YOUR_API_KEY", environment="YOUR_ENVIRONMENT")
现在,我们创建一个名为'hf-endpoints'的新索引,名称并不重要,但dimension必须与我们的端点模型输出维度匹配(我们在上面找到了这个维度),而且模型指标通常是cosine。
Python
index_name = 'hf-endpoints'
# check if the hf-endpoints index exists
if index_name not in pinecone.list_indexes():
# create the index if it does not exist
pinecone.create_index(
index_name,
dimension=dim,
metric="cosine"
)
# connect to hf-endpoints index we created
index = pinecone.Index(index_name)
创建和索引嵌入向量
现在,我们所有的组件都已准备就绪:端点、数据集和Pinecone。让我们开始创建我们的数据集嵌入,并将它们索引在Pinecone上。
Python
from tqdm.auto import tqdm
# we will use batches of 64
batch_size = 64
for i in tqdm(range(0, len(passages), batch_size)):
# find end of batch
i_end = min(i+batch_size, len(passages))
# extract batch
batch = passages[i:i_end]
# generate embeddings for batch via endpoints
res = requests.post(
endpoint,
headers=headers,
json={"inputs": batch}
)
emb = res.json()['embeddings']
# get metadata (just the original text)
meta = [{'text': text} for text in batch]
# create IDs
ids = [str(x) for x in range(i, i_end)]
# add all to upsert list
to_upsert = list(zip(ids, emb, meta))
# upsert/insert these records to pinecone
_ = index.upsert(vectors=to_upsert)
# check that we have all vectors in index
index.describe_index_stats()
100%|██████████| 782/782 [11:02<00:00, 1.18it/s]
{'dimension': 768,
'index_fullness': 0.1,
'namespaces': {'': {'vector_count': 50000}},
'total_vector_count': 50000}
一切都被索引了,我们现在可以开始查询了。我们将从数据集的“premise”列中选取几个例子。
Python
query = snli['premise'][0]
print(f"Query: {query}")
# encode with HF endpoints
res = requests.post(endpoint, headers=headers, json={"inputs": query})
xq = res.json()['embeddings']
# query and return top 5
xc = index.query(xq, top_k=5, include_metadata=True)
# iterate through results and print text
print("Answers:")
for match in xc['matches']:
print(match['metadata']['text'])
Query: A person on a horse jumps over a broken down airplane.
Answers:
The horse jumps over a toy airplane.
a lady rides a horse over a plane shaped obstacle
A person getting onto a horse.
person rides horse
A woman riding a horse jumps over a bar.
这些看起来不错,我们再试几个例子。
Python
query = snli['premise'][100]
print(f"Query: {query}")
# encode with HF endpoints
res = requests.post(endpoint, headers=headers, json={"inputs": query})
xq = res.json()['embeddings']
# query and return top 5
xc = index.query(xq, top_k=5, include_metadata=True)
# iterate through results and print text
print("Answers:")
for match in xc['matches']:
print(match['metadata']['text'])
Query: A woman is walking across the street eating a banana, while a man is following with his briefcase.
Answers:
A woman eats a banana and walks across a street, and there is a man trailing behind her.
A woman eats a banana split.
A woman is carrying two small watermelons and a purse while walking down the street.
The woman walked across the street.
A woman walking on the street with a monkey on her back.
再来多一点:
Python
query = snli['premise'][200]
print(f"Query: {query}")
# encode with HF endpoints
res = requests.post(endpoint, headers=headers, json={"inputs": query})
xq = res.json()['embeddings']
# query and return top 5
xc = index.query(xq, top_k=5, include_metadata=True)
# iterate through results and print text
print("Answers:")
for match in xc['matches']:
print(match['metadata']['text'])
Query: People on bicycles waiting at an intersection.
Answers:
A pair of people on bikes are waiting at a stoplight.
Bike riders wait to cross the street.
people on bicycles
Group of bike riders stopped in the street.
There are bicycles outside.
所有这些结果看起来都很好。如果你不打算在本教程之外继续运行你的端点和向量数据库,可以关闭它们。
一旦删除索引,就不能再使用它。
通过导航到推论端点概述页面并选择删除端点来关闭端点。使用以下命令删除Pinecone索引:
Python
pinecone.delete_index(index_name)
更新于 3个月前