Elasticsearch
Elasticsearch 是一个强大的开源搜索引擎和分析平台,广泛用作基于关键字的文本搜索的文档存储。
Pinecone是一个广泛用于生产应用程序的向量数据库,例如语义搜索、推荐系统和威胁检测,需要在数亿甚至数十亿的嵌入规模上进行快速而新鲜的向量搜索。虽然Pinecone提供关键字感知语义搜索的混合搜索,但Pinecone不是文档存储,也不能替代Elasticsearch进行仅关键字检索。
如果您已经使用Elasticsearch并想将Pinecone的低延迟和大规模向量搜索添加到您的应用程序中,本指南将向您展示如何实现。您将了解如何:
在Elasticsearch中添加嵌入模型
将文本数据转换为Elasticsearch中的向量嵌入
将这些向量嵌入与相应的ID和元数据一起加载到Pinecone中。
上传嵌入模型
我们首先需要将嵌入式模型上传到Elastic实例中。为此,我们将使用[eland](https://github.com/elastic/eland) Elastic客户端。在运行它之前,我们需要克隆"eland"存储库并构建Docker镜像。
Bash
git clone [[email protected]](https://docs.pinecone.io/cdn-cgi/l/email-protection):elastic/eland.git
cd eland
docker build -t elastic/eland .
在本示例中,我们将使用Hugging Face的[sentence-transformers/msmarco-MiniLM-L-12-v3](https://huggingface.co/sentence-transformers/msmarco-MiniLM-L-12-v3)模型——尽管您可以使用任何您喜欢的模型。要将模型上传到您的Elasticsearch部署中,请运行以下命令:
Bash
docker run -it --rm elastic/eland \
eland_import_hub_model \
--url https://<user>:<password>@<host>:<port>/ \
--hub-model-id sentence-transformers/msmarco-MiniLM-L-12-v3 \
--task-type text_embedding \
--start
请注意,您需要用您的Elasticsearch实例用户、密码、主机和端口替换占位符。如果您设置了自己的Elasticsearch实例,您在最初设置实例时已经设置了用户名和密码。如果您正在使用托管的Elastic Stack,则可以在Elastic Stack控制台的“安全性”部分找到用户名和密码。
我们可以在Elasticsearch开发者控制台中运行以下命令来快速测试上传的模型:
POST /_ml/trained_models/sentence-transformers__msmarco-minilm-l-12-v3/deployment/_infer
{
"docs": {
"text_field": "Hello World!"
}
}
我们应该得到以下结果:
JSON
{
"predicted_value": [
-0.06176435202360153,
-0.008180409669876099,
0.3309500813484192,
0.38672536611557007,
...
]
}
这是我们查询的向量嵌入。我们现在准备上传我们的数据集并应用模型以生成向量嵌入。
上传数据集
接下来,将一组文件文档上传到Elasticsearch。在本示例中,我们将使用MSMarco数据集的子集。您可以下载文件或运行以下命令:
Bash
curl -O https://msmarco.blob.core.windows.net/msmarcoranking/msmarco-passagetest2019-top1000.tsv.gz
gunzip msmarco-passagetest2019-top1000.tsv
在本例中,我们将使用托管的Elastic Stack,这使得使用各种集成更加容易。 我们将使用“Upload”集成将数据加载到Elasticsearch索引中。
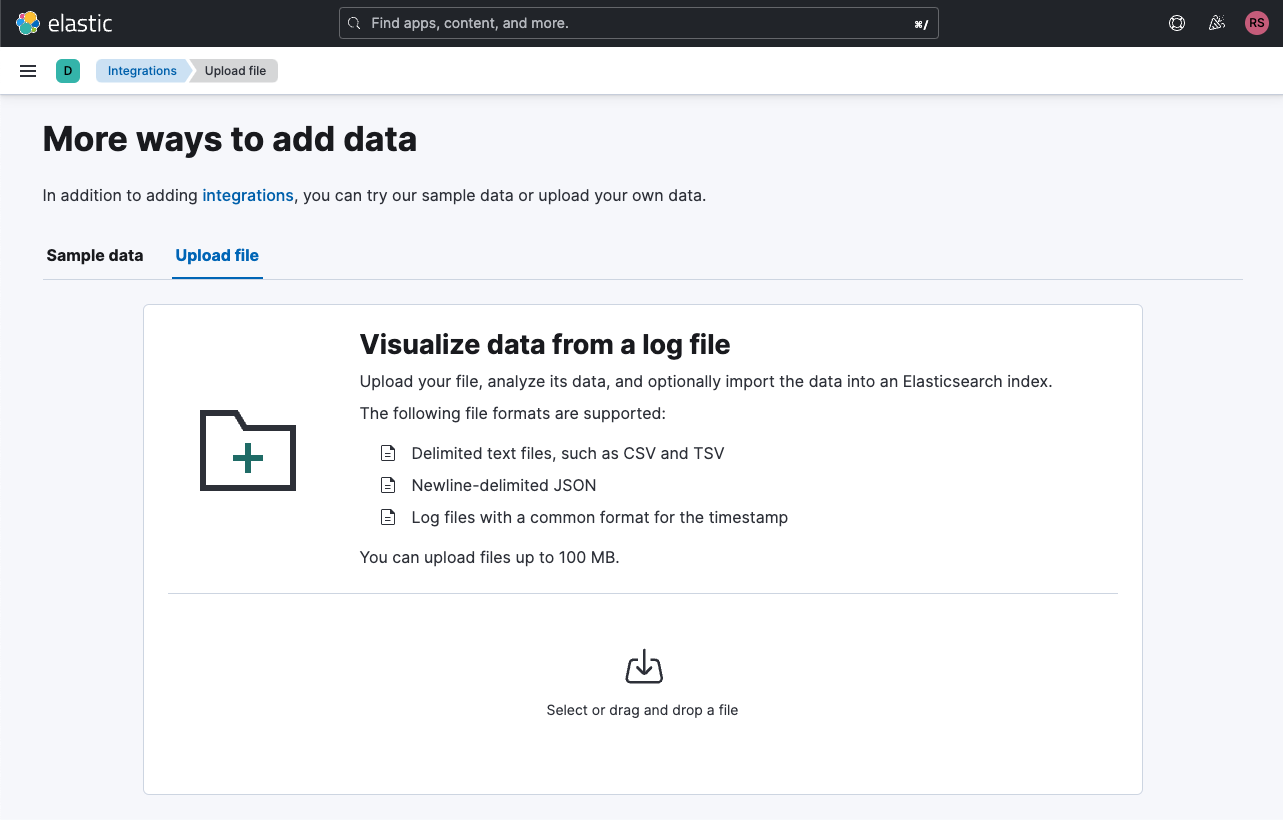
我们将拖动解压缩后的TSV文件。 Upload集成将为我们抽样数据并显示以下内容:
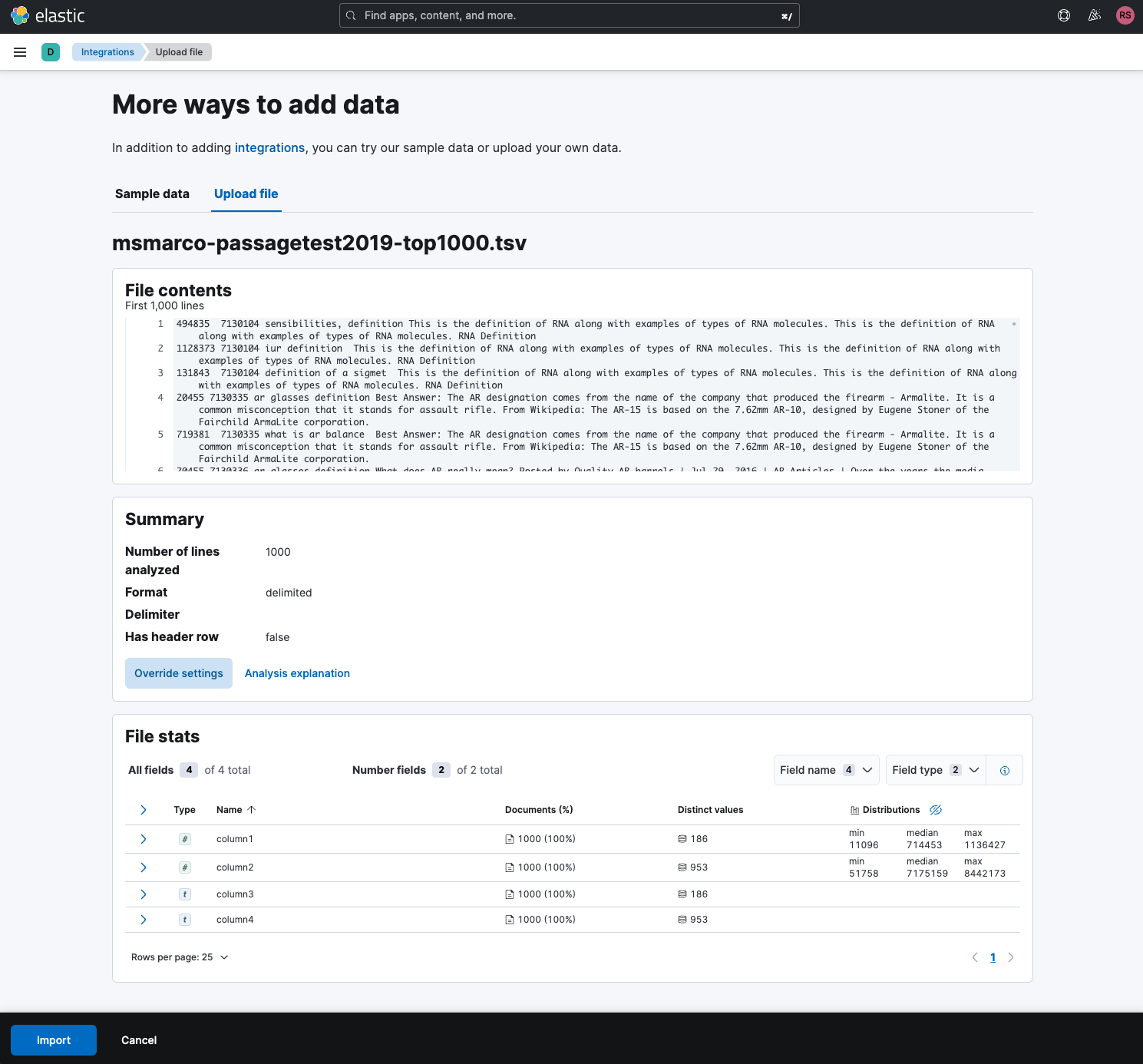
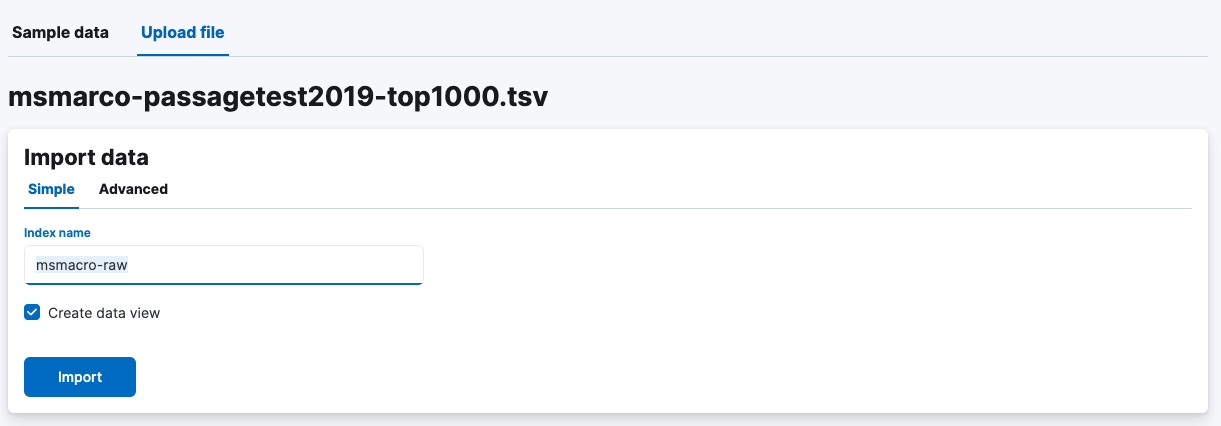
我们将点击“Import”按钮,并继续为索引命名:
导入完成后,您将看到以下内容:
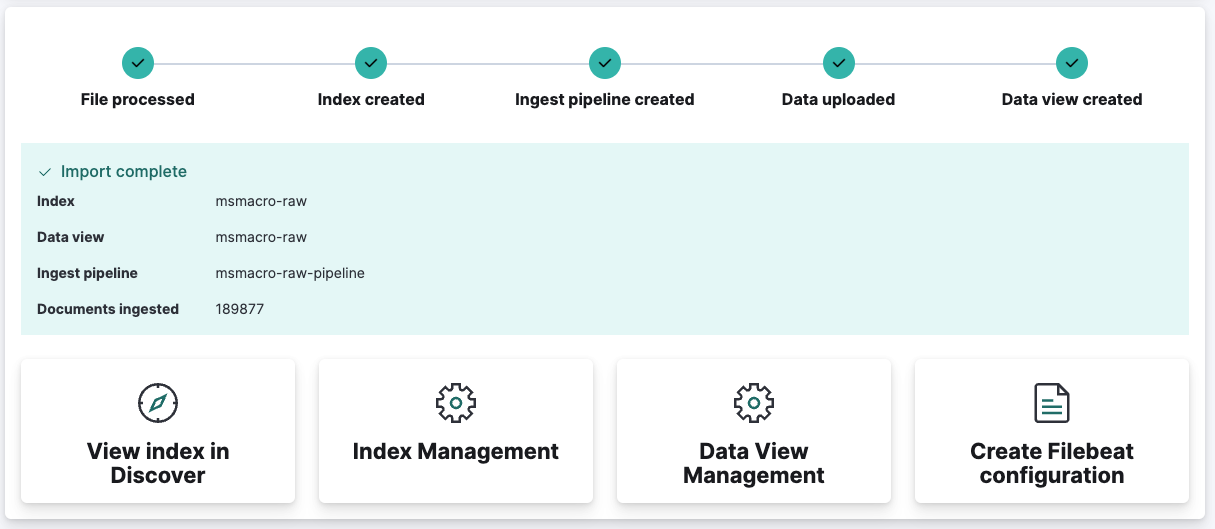
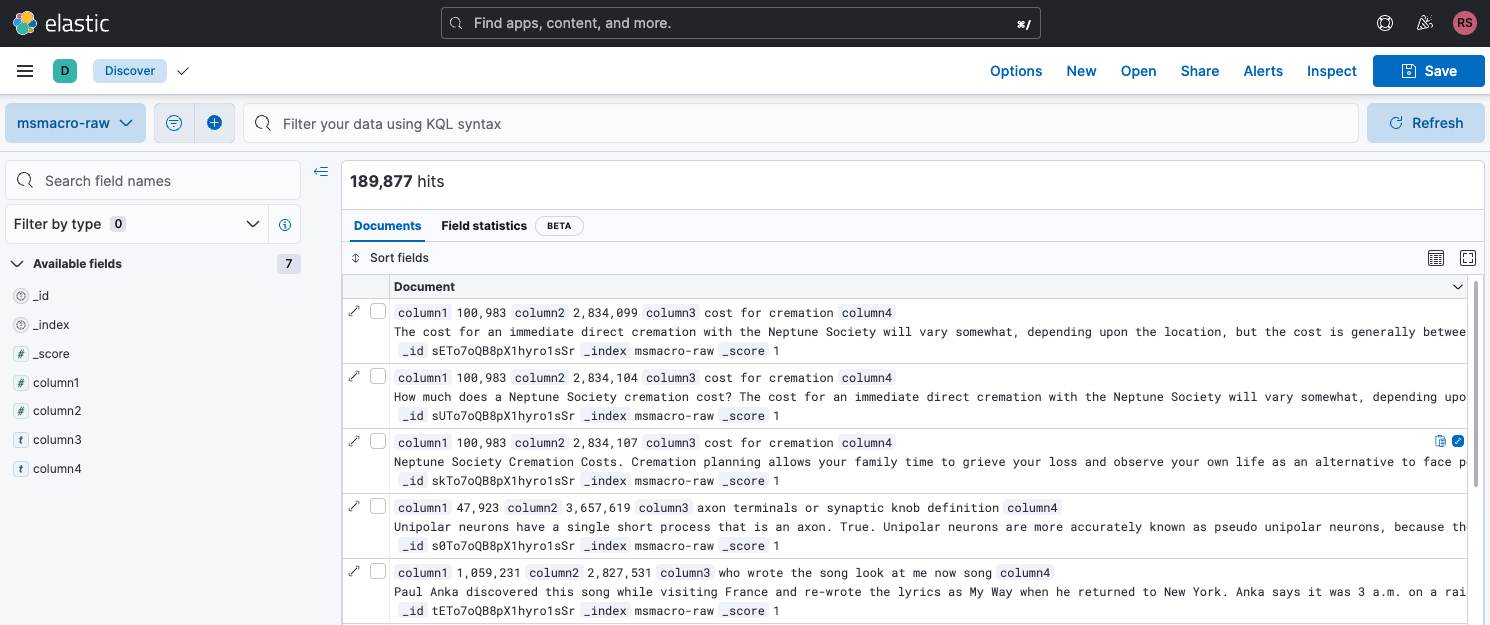
单击“Discover中查看索引”将显示索引视图,我们可以在其中查看已上传的数据:
创建嵌入
我们已经为数据创建了索引。接下来,我们将创建一个管道为每个文档生成向量嵌入。我们将前往Elasticsearch开发人员控制台并发出以下命令来创建管道:
PUT _ingest/pipeline/produce-embeddings
{
"description": "Vector embedding pipeline",
"processors": [
{
"inference": {
"model_id": "sentence-transformers__msmarco-minilm-l-12-v3",
"target_field": "text_embedding",
"field_map": {
"text": "text_field"
}
}
}
],
"on_failure": [
{
"set": {
"description": "Index document to 'failed-<index>'",
"field": "_index",
"value": "failed-{{{_index}}}"
}
},
{
"set": {
"description": "Set error message",
"field": "ingest.failure",
"value": "{{_ingest.on_failure_message}}"
}
}
]
}
“processor”定义告诉Elasticsearch使用哪个模型以及从哪个字段读取。 “on_failure”定义定义Elasticsearch将应用的故障行为-特别是要写入哪个错误消息以及要将其写入哪个文件中。
创建嵌入管道后,我们将重新索引我们的“msmacro-raw”索引,应用嵌入管道以生成新的嵌入。在开发人员控制台中,执行以下命令:
POST _reindex?wait_for_completion=false
{
"source": {
"index": "msmacro-raw"
},
"dest": {
"index": "msmacro-with-embeddings",
"pipeline": "text-embeddings"
}
}
这将启动嵌入管道。我们将获得一个任务ID,可以使用以下命令跟踪:
GET _tasks/<task_id>
查看索引,我们可以看到嵌入已在“predicted_value”字段下的名为“text_embeddings”的对象中创建。
为了使加载过程更加容易,我们将拔掉“predicted_value”字段并将其添加为自己的列:
POST _reindex?wait_for_completion=false
{
"source": {
"index": "msmacro-with-embeddings"
},
"dest": {
"index": "msmacro-with-embeddings-flat"
},
"script": {
"source": "ctx._source.predicted_value = ctx._source.text_embedding.predicted_value"
}
}
接下来,我们将加载嵌入到Pinecone中。由于索引大小相当大,我们将使用Apache Spark并行化过程。
将Elasticsearch索引移动到Pinecone
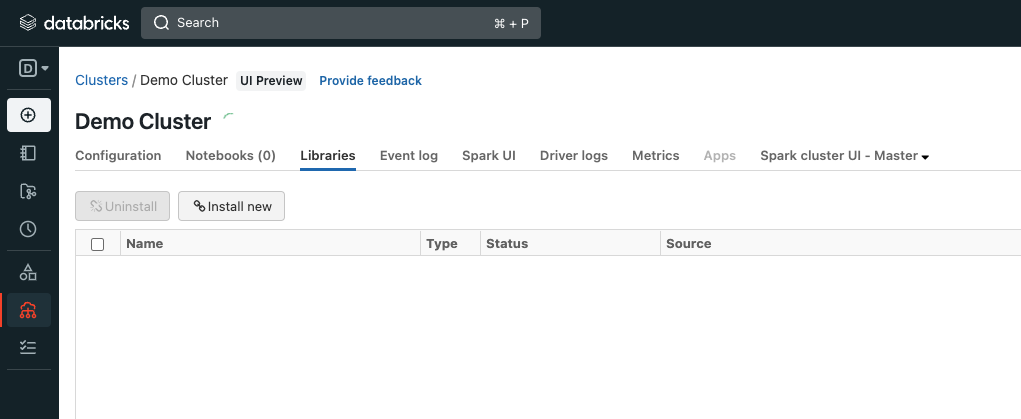
在本例中,我们将使用Databricks来处理将Elasticsearch索引加载到Pinecone的过程。我们将通过在集群设置视图中导航到“Libraries”选项卡,并单击“安装新程序包”来添加Maven中的Elasticsearch Spark:
使用以下Maven坐标:
org.elasticsearch:elasticsearch-spark-30_2.12:8.5.2
我们将从S3添加Pinecone Databricks连接器:
s3://pinecone-jars/spark-pinecone-uberjar.jar
如果需要,重启集群。接下来,我们将创建一个新的笔记本,将其附加到集群并导入所需的依赖项:
Scala
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.elasticsearch.spark._
我们将初始化Spark上下文:
Scala
val spark = SparkSession.builder.appName("elasticSpark").master("local[*]").getOrCreate()
接下来,我们将从Elasticsearch读取索引:
Scala
val df = (spark.read
.format( "org.elasticsearch.spark.sql" )
.option( "es.nodes", "<ELASTIC_URL>" )
.option( "es.net.http.auth.user", "<ELASTIC_USER>" )
.option( "es.net.http.auth.pass", "<ELASTIC_PASSWORD>" )
.option( "es.port", 443 )
.option( "es.nodes.wan.only", "true" )
.option("es.net.ssl", "true")
.option("es.read.field.as.array.include","predicted_value:1")
.load( "msmacro-with-embeddings")
)
请注意,为了确保将索引正确读入数据帧中,我们必须指定“predicted_value”字段是一个深度为1的数组,如下所示:
Scala
.option("es.read.field.as.array.include","predicted_value:1")
接下来,我们将使用Pinecone Spark连接器将此数据框加载到Pinecone索引中。首先,在Pinecone控制台中创建一个索引。登录到控制台,然后单击“创建索引”。然后,命名您的索引,并配置它使用384个维度。
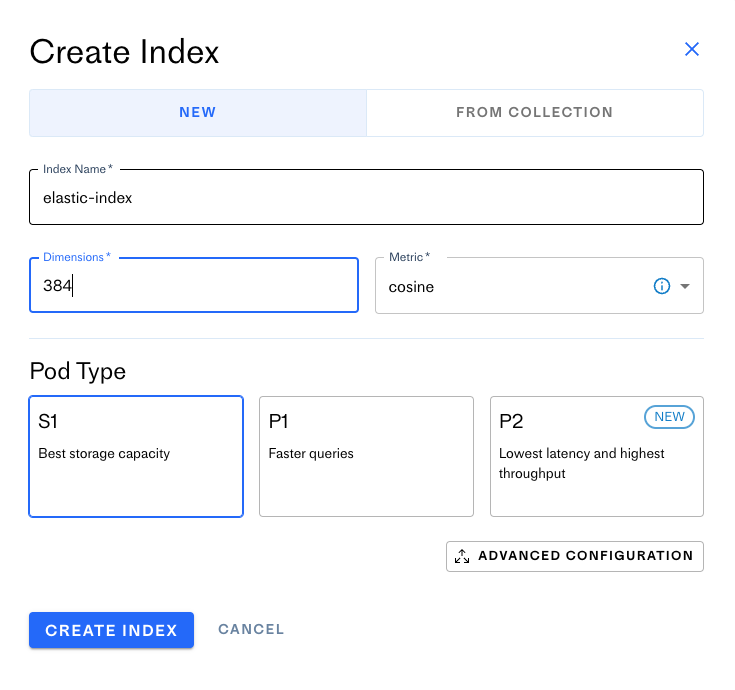
当您完成配置索引后,请单击“创建索引”。
我们需要进行一些准备工作,使数据框准备好进行索引。为了使用我们创建的嵌入将原始文档进行索引,我们将创建以下UDF,该UDF将原始文档编码为Base64字符串。这将确保元数据对象始终是有效的JSON对象,无论文档的内容如何。
Scala
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions.udf
import java.util.Base64
val text_to_metadata = udf((text: String) => "{ \"document\" : \"" + Base64.getEncoder.encodeToString(text.getBytes("UTF-8")) + "\" }")
我们将应用UDF并摆脱一些不必要的列:
Scala
val clean_df = df.drop("text_embedding").withColumnRenamed("predicted_value", "vector").withColumn("metadata", text_to_metadata(col("text_field"))).withColumn("namespace", lit("")).drop("text_field")
接下来,我们将使用Pinecone Spark连接器:
Scala
val pineconeOptions = Map(
"pinecone.apiKey" -> "<PINECONE_API_KEY>",
"pinecone.environment" -> "us-west1-gcp",
"pinecone.projectName" -> "<PROJECT_IDENTIFIER>",
"pinecone.indexName" -> "elastic-index"
)
clean_df.write
.options(pineconeOptions)
.format("io.pinecone.spark.pinecone.Pinecone")
.mode(SaveMode.Append)
.save()
我们的向量已添加到Pinecone索引中!
To query the index, we’ll need to generate a vector embedding for our query first, using the sentence-transformers/msmarco-MiniLM-L-12-v3 model. Then, we’ll use the Pinecone client to issue the query. We'll do this in a Python notebook.
我们将首先安装所需的依赖项:
!pip install -qU pinecone-client sentence-transformers pandas
接下来,我们将设置客户端:
Python
import pinecone
# connect to pinecone environment
pinecone.init(
api_key="<PINECONE API KEY>",
environment="us-west1-gcp"
)
我们将设置索引:
Python
index_name = "elastic-index"
index = pinecone.Index(index_name)
我们将创建一个帮助函数,用于解码我们获取的编码文档:
Python
def decode_entries(entries):
return list(map(lambda entry: {
"id": entry["id"],
"score": entry["score"],
"document": base64.b64decode(entry["metadata"]["document"]).decode("UTF-8"),
}, entries))
接下来,我们将创建一个函数,将编码查询,查询索引并使用Pandas转换和显示数据:
Python
def queryIndex(query, num_results):
vector = model.encode(query).tolist()
result = index.query(vector, top_k=num_results, include_metadata=True)
return pd.DataFrame(decode_entries(result.matches))
最后,我们将测试我们的索引:
Python
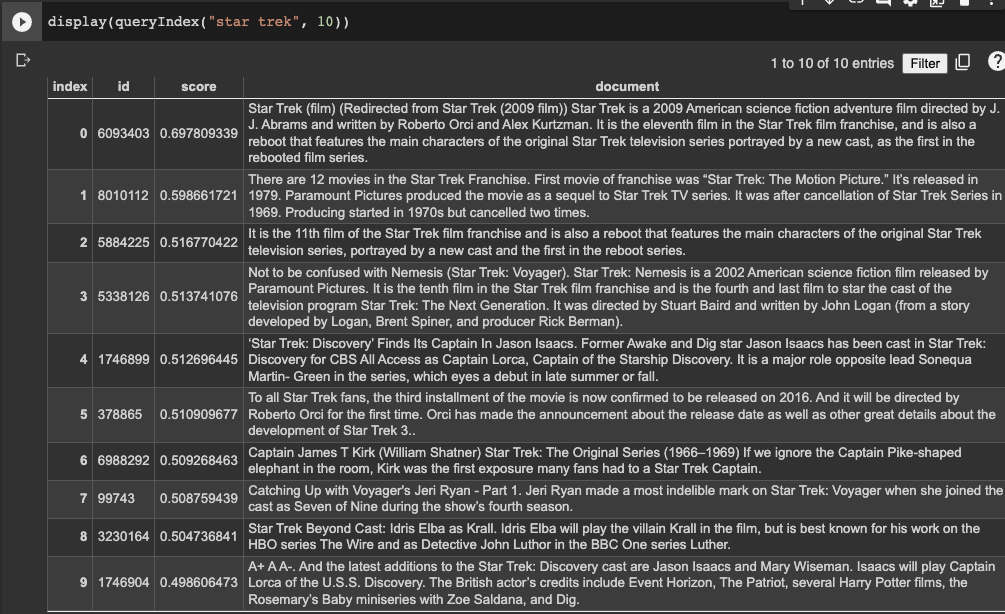
display(queryIndex("star trek", 10))
Should yield the results:
概要
总之,按照本文概述的步骤,您可以轻松地将嵌入式模型上传到Elasticsearch,摄入原始文本数据,创建嵌入式向量,并将其加载到Pinecone中。通过这种方法,您可以利用集成Elasticsearch和Pinecone的优势。正如提到的那样,虽然Elasticsearch针对索引文档进行了优化,但Pinecone提供了可以处理数亿甚至数十亿向量的向量存储和搜索功能。
更新时间:5个月前