Cohere
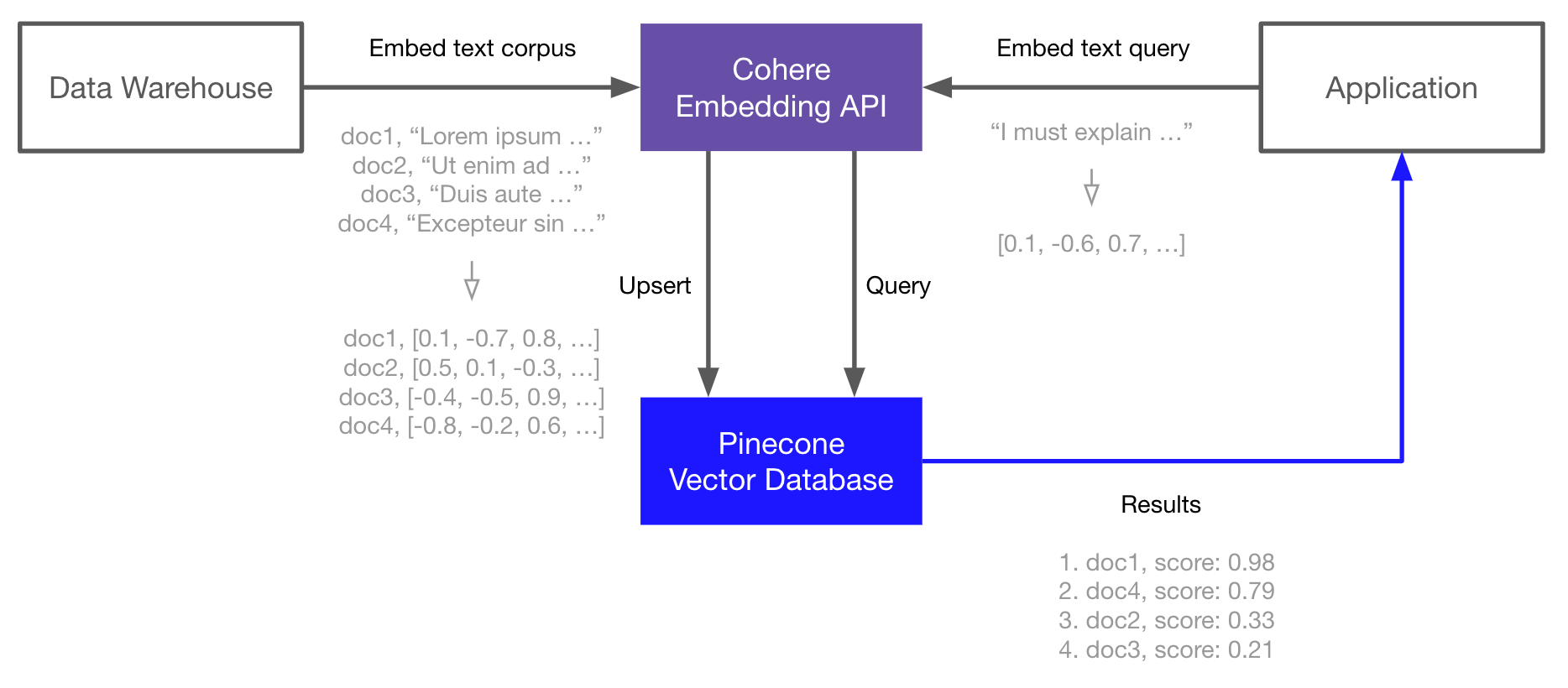
在本指南中,您将学习如何使用Cohere嵌入API终端点生成语言嵌入,然后将这些嵌入索引到Pinecone矢量数据库中,以进行快速和可扩展的矢量搜索。
这是构建语义搜索、问答、威胁检测和其他依赖于NLP和对大量文本数据进行搜索的应用程序的强大和常见组合。
基本工作流程如下:
嵌入和索引
- 使用Cohere嵌入API终端点生成文档(或任何文本数据)的向量嵌入。
- 将这些向量嵌入上传到Pinecone中,它可以存储和索引数百万/十亿个这些向量嵌入,并以极低的延迟进行搜索。
搜索
- 再次通过Cohere嵌入API终端点传递您的查询文本或文档。
- 将结果向量嵌入作为查询发送到Pinecone。
- 获取语义上相似的文档,即使它们与查询没有共享任何关键字。
让我们开始吧...
https://files.readme.io/fd0ba7b-pinecone-cohere-overview.png
环境设置
我们从安装Cohere和Pinecone客户端开始,我们还需要使用HuggingFace Datasets下载我们在本指南中将使用的TREC数据集。
Bash
pip install -U cohere pinecone-client datasets
创建嵌入
要创建嵌入,我们必须首先初始化与Cohere的连接,我们可以在Cohere上注册API密钥。
Python
import cohere
co = cohere.Client("<<YOUR_API_KEY>>")
我们将加载“文本检索会议”(TREC)问题分类数据集,其中包含5.5K个标记的问题。我们将取前1K个样本进行演示,但这可以扩展到数百万甚至数十亿个样本。
Python
from datasets import load_dataset
# load the first 1K rows of the TREC dataset
trec = load_dataset('trec', split='train[:1000]')
在trec中,每个样本都包含两个标签特征和我们将使用的text特征。我们可以将text特征的问题传递给Cohere以创建嵌入。
Python
embeds = co.embed(
texts=trec['text'],
model='small',
truncate='LEFT'
).embeddings
我们可以检查返回向量的维度,为此,我们将其从列表的列表转换为Numpy数组。我们需要保存从中提取的嵌入维度,以便在稍后初始化我们的Pinecone索引时使用。
Python
import numpy as np
shape = np.array(embeds).shape
print(shape)
[Out]:
(1000, 1024)
在这里,我们可以看到Cohere的小型模型生成的1024嵌入维度以及我们为之构建嵌入的1000个样本。
存储嵌入
现在我们已经有了我们的嵌入,我们可以将它们索引到Pinecone向量数据库中。为此,我们需要一个Pinecone API密钥,在这里注册一个。
我们首先初始化与Pinecone的连接,然后创建一个新的索引用于存储嵌入(我们将其称为"cohere-pinecone-trec")。在创建索引时,我们指定要使用余弦相似度度量来与Cohere的嵌入对齐,并传递1024的嵌入维度。
Python
import pinecone
# initialize connection to pinecone (get API key at app.pinecone.io)
pinecone.init(api_key="YOUR_API_KEY", environment="YOUR_ENVIRONMENT")
index_name = 'cohere-pinecone-trec'
# if the index does not exist, we create it
if index_name not in pinecone.list_indexes():
pinecone.create_index(
index_name,
dimension=shape[1],
metric='cosine'
)
# connect to index
index = pinecone.Index(index_name)
现在我们可以开始用我们的嵌入来填充索引了。Pinecone希望我们提供一个元组列表,格式为(id,vector,metadata),其中metadata字段是一个可选的额外字段,在其中我们可以以字典格式存储任何想要的内容。对于这个例子,我们将存储嵌入的原始文本。
⚠️警告
高基数的元数据值(如我们在这里使用的唯一文本值)
可能会减少适合单个pod的向量数量。更多信息请参见
限制。
在上传我们的数据时,我们将批量处理所有内容,以避免一次推送过多的数据。
Python
batch_size = 128
ids = [str(i) for i in range(shape[0])]
# create list of metadata dictionaries
meta = [{'text': text} for text in trec['text']]
# create list of (id, vector, metadata) tuples to be upserted
to_upsert = list(zip(ids, embeds, meta))
for i in range(0, shape[0], batch_size):
i_end = min(i+batch_size, shape[0])
index.upsert(vectors=to_upsert[i:i_end])
# let's view the index statistics
print(index.describe_index_stats())
[Out]:
{'dimension': 1024,
'index_fullness': 0.0,
'namespaces': {'': {'vector_count': 1000}}}
从index.describe_index_stats可知,我们有一个包含1000个嵌入的1024维度的索引。indexFullness度量告诉我们索引有多满,目前是空的。使用默认值的单个p1 Pod,我们可以在indexFullness达到容量之前存储大约750K个嵌入。可以使用使用估算器来确定存储给定数量的n维嵌入所需的Pod数量。
语义搜索
现在我们有了我们的索引向量,我们可以执行一些搜索查询。在搜索时,我们将首先使用Cohere嵌入我们的查询,然后使用Pinecone返回的向量进行搜索。
Python
query = "What caused the 1929 Great Depression?"
# create the query embedding
xq = co.embed(
texts=[query],
model='small',
truncate='LEFT'
).embeddings
print(np.array(xq).shape)
# query, returning the top 5 most similar results
res = index.query(xq, top_k=5, include_metadata=True)
Pinecone的响应包括metadata字段中的原始文本,让我们打印出top_k个最相似的问题及其相似度分数。
Python
for match in res['matches']:
print(f"{match['score']:.2f}: {match['metadata']['text']}")
[Out]:
0.83: Why did the world enter a global depression in 1929 ?
0.75: When was `` the Great Depression '' ?
0.50: What crop failure caused the Irish Famine ?
0.34: What war did the Wanna-Go-Home Riots occur after ?
0.34: What were popular songs and types of songs in the 1920s ?
看起来不错,让我们让它更难一些,用不正确的术语“衰退”代替“抑郁症”。
Python
query = "What was the cause of the major recession in the early 20th century?"
# create the query embedding
xq = co.embed(
texts=[query],
model='small',
truncate='LEFT'
).embeddings
# query, returning the top 5 most similar results
res = index.query(xq, top_k=5, include_metadata=True)
for match in res['matches']:
print(f"{match['score']:.2f}: {match['metadata']['text']}")
[Out]:
0.66: Why did the world enter a global depression in 1929 ?
0.61: When was `` the Great Depression '' ?
0.43: What are some of the significant historical events of the 1990s ?
0.43: What crop failure caused the Irish Famine ?
0.37: What were popular songs and types of songs in the 1920s ?
让我们使用抑郁症的定义而不是单词或相关单词进行最后一次搜索。
Python
query = "Why was there a long-term economic downturn in the early 20th century?"
# create the query embedding
xq = co.embed(
texts=[query],
model='small',
truncate='LEFT'
).embeddings
# query, returning the top 10 most similar results
res = index.query(xq, top_k=10, include_metadata=True)
for match in res['matches']:
print(f"{match['score']:.2f}: {match['metadata']['text']}")
[Out]:
0.71: Why did the world enter a global depression in 1929 ?
0.62: When was `` the Great Depression '' ?
0.40: What crop failure caused the Irish Famine ?
0.38: What are some of the significant historical events of the 1990s ?
0.38: When did the Dow first reach ?
从这个例子中可以清楚地看出,语义搜索管道能够清楚地识别每个查询之间的含义。使用这些嵌入与Pinecone一起,我们可以从已索引的TREC数据集返回最具语义相似性的问题。
更新时间 3个月前