数据湖
使用Databricks和Pinecone在规模上创建和索引向量嵌入
建立在Apache Spark之上的Databricks是一个强大的数据处理和分析平台,以高效处理大型数据集而闻名。在本指南中,我们将向您展示如何使用Spark(与Databricks)创建向量嵌入并将它们加载到Pinecone中。
首先,让我们讨论为什么在这种情况下使用Databricks和Pinecone是必要的。当您处理不到一百万条记录时,使用单台机器可能足够。但是当您处理数亿条记录时,您必须开始考虑操作的规模。我们需要考虑两件事:
如何在规模上高效地生成嵌入?
在规模上,我们能够高效地摄取和更新这些嵌入吗?
Databricks是一个非常好的在规模上创建嵌入的工具:它允许我们在多个机器上并行处理并利用GPU加速处理过程。
Pinecone让我们能够高效地摄取、更新和查询数亿甚至数十亿个嵌入。作为托管服务,Pinecone在处理这种规模的数据集时可以保证非常高的可靠性和性能。
Pinecone为Databricks提供了一个专门的连接器,优化了从Databricks摄取数据到Pinecone的过程。这使得在大规模数据集上使用Pinecone的REST或gRPC API相比之下,数据摄取过程可以更快地完成。
结合Pinecone和Databricks,可以很好地管理规模化的向量嵌入的整个生命周期。
为什么选择Databricks?
Databricks是基于Apache Spark的统一分析平台。使用Spark的主要优势在于其能够将工作负载分布在一组机器上,从而快速高效地处理大量数据。通过增加机器或增加每台机器上的核心数,可以很容易地横向扩展集群以处理更大的工作负载。
Spark的核心是map-reduce模式,数据被分成多个分区,然后对每个分区并行进行一系列的转换。每个分区的结果会被自动收集和聚合到最终结果中。这种方法使得Spark既快速又容错,因为它可以在不需要重新处理整个工作负载的情况下重试失败的任务。
除了其并行处理能力之外,Spark还允许开发人员使用流行的编程语言(如Python和Scala)编写代码,这些代码在底层进行了并行执行的优化。这使得开发人员更容易专注于数据处理本身,而不必担心分布式计算的细节。
向量嵌入是一项计算密集型任务,其中并行化可以节省大量珍贵的计算时间和资源。利用Spark的GPU可以产生更好的结果-享受GPU快速计算和并行化的好处将确保最佳性能。
Databricks使得与Apache Spark一起工作更加容易:它提供了易于设置和拆除集群、依赖管理、计算分配、存储解决方案集成等功能。
为什么选择Pinecone?
Pinecone是一个向量数据库,可轻松构建高性能的向量搜索应用程序。它提供了许多关键优势,包括在任何规模下的超低查询延迟、添加、编辑或删除数据时进行实时索引更新以及将向量搜索与元数据过滤或关键字搜索相结合,以获得更相关的结果。如前所述,Pinecone可以轻松处理数亿甚至数十亿的向量嵌入。此外,Pinecone是完全托管的,因此易于使用和扩展。
使用Pinecone,您可以轻松地索引和搜索向量嵌入。它非常适合各种用例,例如语义文本搜索、问答、视觉搜索、推荐系统等。
在此示例中,我们将基于Hugging Face的sentence-transformers/all-MiniLM-L6-v2模型创建嵌入。然后,我们将使用具有大量文档的数据集来生成嵌入并将其upsert到Pinecone中。请注意,我们将使用的实际模型和数据集对于此示例来说并不重要。这种方法适用于您可能想创建的任何嵌入,以及您可能选择的任何数据集。
为了批量创建嵌入,我们需要做四件事:
设置Spark集群
将数据集加载到分区中
对每个条目应用嵌入模型以生成嵌入
保存结果
让我们开始吧!
设置Spark集群
使用Databricks可以通过在我们的集群中使用GPU而不是CPU来更轻松地加速嵌入的创建。要这样做,请在Databricks控制台的“计算”部分中导航,并选择以下选项:
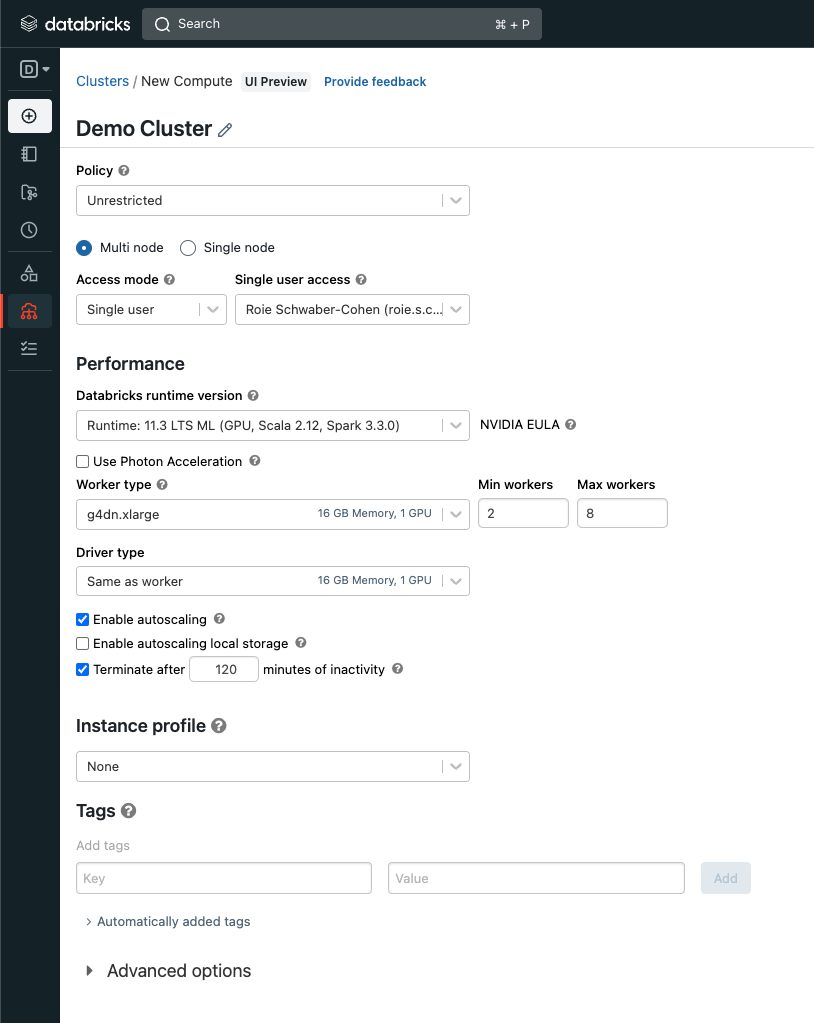
接下来,我们将添加Pinecone Spark连接器到我们的集群中。导航到“库”选项卡,然后点击“安装”新的。
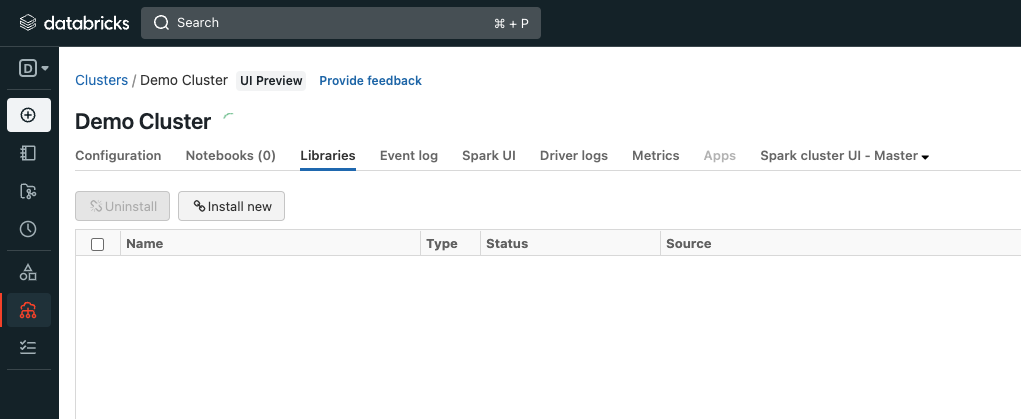
选择“DBF”/S3”,并粘贴以下S3 URI:
s3://pinecone-jars/spark-pinecone-uberjar.jar
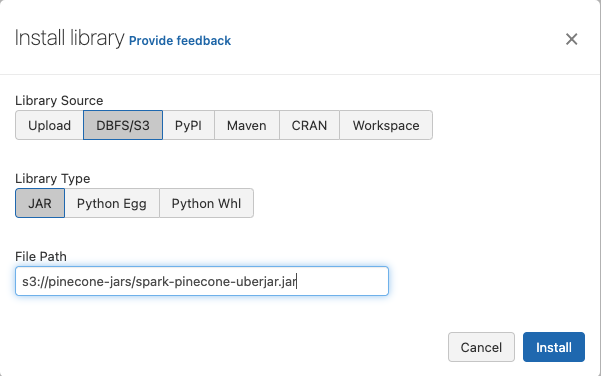
完成安装后,点击“安装”。要使用新的集群,请创建一个新的笔记本并将其附加到新创建的集群。
环境设置
首先,我们需要安装一些依赖:
%pip install datasets transformers pinecone-client torch
接下来,我们将设置与Pinecone的连接。您需要从您的Pinecone控制台检索以下信息:
- API密钥:导航到您的项目并在侧边栏上单击“API密钥”按钮
- 环境:检查浏览器的URL以获取当前环境。
https://app.pinecone.io/organizations/[org-id]/projects/[environment]:[project_name]/indexes
您的索引名称将与我们初始化索引时使用的索引名称相同(在本例中为news)。
Python
import pinecone
api_key = # <YOUR_PINECONE_API_KEY>
environment = 'us-west1-gcp'
pinecone.init(api_key=api_key, environment=environment)
接下来,我们将在Pinecone中创建一个新索引,将嵌入向量保存在其中:
Python
index_name = 'news'
if index_name in pinecone.list_indexes():
pinecone.delete_index(index_name)
pinecone.create_index(name=index_name, dimension=384)
index = pinecone.Index(index_name=index_name)
将数据集加载到分区中
在本例中,我们将使用一组新闻文章作为我们的示例数据集。我们将使用Hugging Face的数据集库将数据加载到我们的环境中:
Python
from datasets import list_datasets, load_dataset
dataset_name = "allenai/multinews_sparse_max"
dataset = load_dataset(dataset_name, split="train")
接下来,我们将从Hugging Face格式转换数据集并重新分区:
Python
dataset.to_parquet('/dbfs/tmp/dataset_parquet.pq')
num_workers = 10
dataset_df = spark.read.parquet('/tmp/dataset_parquet.pq').repartition(num_workers)
重新分区完成后,我们会获得一个DataFrame,它是一个分布式的数据集合,可以按命名列组织数据。它在概念上相当于关系数据库中的表或R/Python中的数据帧,但在内部进行了更丰富的优化。正如上面提到的,数据框中的每个分区都具有相等数量的原始数据。
数据集中没有与每个文档相关联的标识符,因此让我们添加它们:
Python
from pyspark.sql.types import StringType
from pyspark.sql.functions import monotonically_increasing_id
dataset_df = dataset_df.withColumn('id', monotonically_increasing_id().cast(StringType()))
如其名称所示,withColumn将一个包含简单递增标识符的列添加到数据框中,我们将其转换为字符串。很好!现在我们为每个文档都有了标识符。接下来让我们开始创建每个文档的嵌入。
创建将文本转换为嵌入的函数
在这个示例中,我们将创建一个UDF(用户定义的函数)来创建嵌入,使用Hugging Face transformers库中的AutoTokenizer和AutoModel类。UDF将应用于数据框中的每个分区。当应用于分区时,UDF在分区中的每一行上执行。UDF将使用AutoTokenizer对文档进行标记化,然后将结果传递给模型(在这种情况下,我们使用sentence-transformers/all-MiniLM-L6-v2)。最后,我们通过从结果中提取最后一个隐藏层来生成嵌入本身。
一旦创建了UDF,它就可以应用于数据框中,以转换指定列中的数据。 Python UDF 将发送到 Spark 工作者节点,用于转换数据。 转换完成后,结果将被发送回驱动程序,并存储在新列中。
Python
from transformers import AutoTokenizer, AutoModel
def create_embeddings(partitionData):
tokenizer = AutoTokenizer.from_pretrained("sentence-transformers/all-MiniLM-L6-v2")
model = AutoModel.from_pretrained("sentence-transformers/all-MiniLM-L6-v2")
for row in partitionData:
document = str(row.document)
inputs = tokenizer(document, padding=True, truncation=True, return_tensors="pt", max_length=512)
result = model(**inputs)
embeddings = result.last_hidden_state[:, 0, :].cpu().detach().numpy()
lst = embeddings.flatten().tolist()
yield [row.id, lst, '', '{}']
将UDF应用于数据
Spark中的dataframe是建立在一种更基本的构建块——弹性分布式数据集(Resilient Distributed Dataset或简称RDD)的更高级抽象。我们将使用mapPartitions函数,在RDD的每个分区中显式应用我们的UDF,从而更精细地控制UDF的执行。
Python
embeddings = dataset_df.rdd.mapPartitions(create_embeddings)
接下来,我们将使用 Pinecone 所需的模式将生成的 RDD 转换回数据框:
Python
from pyspark.sql.types import StructType,StructField, ArrayType, FloatType
schema = StructType([
StructField("id",StringType(),True),
StructField("vector",ArrayType(FloatType()),True),
StructField("namespace",StringType(),True),
StructField("metadata", StringType(), True),
])
embeddings_df = spark.createDataFrame(data=embeddings,schema=schema)
更新嵌入
最后,我们将使用 Pinecone Spark 连接器将嵌入保存到索引中。
Python
(
df.write
.option("pinecone.apiKey", api_key)
.option("pinecone.environment", environment)
.option("pinecone.projectName", pinecone.whoami().projectname)
.option("pinecone.indexName", index_name)
.format("io.pinecone.spark.pinecone.Pinecone")
.mode("append")
.save()
)
将嵌入写入Pinecone的过程需要大约15秒钟。当它完成时,您将看到以下内容:
spark: org.apache.spark.sql.SparkSession = [[电子邮件保护]](https://docs.pinecone.io/cdn-cgi/l/email-protection)
pineconeOptions: scala.collection.immutable.Map[String,String] = Map(pinecone.apiKey -><YOUR API KEY>, pinecone.environment -> us-west1-gcp, pinecone.projectName -><YOUR PROJECT NAME>, pinecone.indexName -> "news")
这意味着过程已经成功完成,嵌入已存储在Pinecone中。
摘要
为大型数据集创建向量嵌入可能具有挑战性,但Databricks是实现该任务的一个很好的工具。 Databricks使设置GPU集群和处理所需的依赖项变得容易,从而允许高效地创建规模的嵌入。
Databricks和Pinecone是处理非常大的向量数据集的完美组合。 Pinecone提供了一种有效地存储和检索Databricks创建的向量的方法,使得处理大量向量变得容易和高效。 总的来说,Databricks和Pinecone的组合提供了一个强大而有效的解决方案,可用于创建非常大的数据集的嵌入。 通过并行化嵌入生成和数据摄入过程,我们可以创建一个快速而弹性的管道,能够索引和更新大量向量。
更新于4个月前